

HANA DB Fundamentals II – Der Delta Store

Dieser Beitrag ist der zweite Teil unserer „HANA DB Fundamentals“. Im ersten Teil erklären wir, was Spaltenorientierung bedeutet. Darauf aufbauend widmen wir uns einem weiteren Teil der HANA DB, dem Delta Store. Worum handelt es sich dabei und warum wird er in der HANA DB eingesetzt?
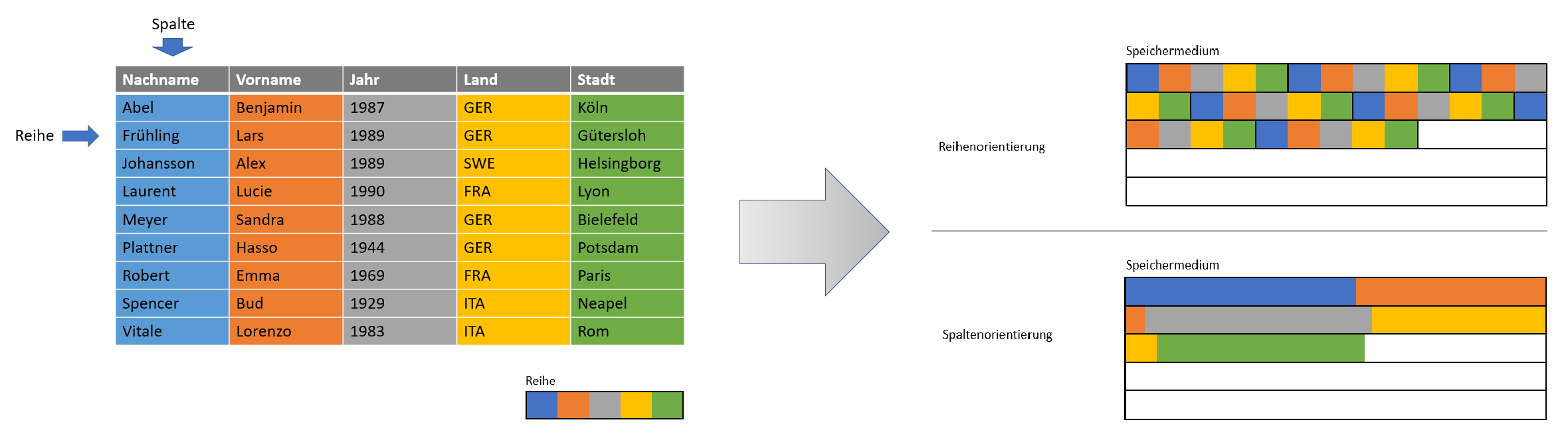
Reihen- und Spaltenorientierung
Wir haben bereits festgestellt, dass es bei Reihen- und Spaltenorientierung im Wesentlichen um das Speichern und Lesen von Daten geht. Je nach Datenbankkooperation ist die eine oder die andere Orientierung von Vorteil.
Zum besseren Verständnis benötigen wir noch einen sehr kurzen Ausflug in die Hardwaretechnik.
Das Speichern und Lesen von Daten
Das Speichern und Lesen von Daten erfolgt immer in festgelegten Einheiten, sogenannten Datenblöcken. Datenblöcke haben durch die verwendete Hardware festgelegte Größen. Es ist also die Regel, dass ein Datenblock mehrere Einträge einer Tabelle enthält.
Der Reconstruction Overhead
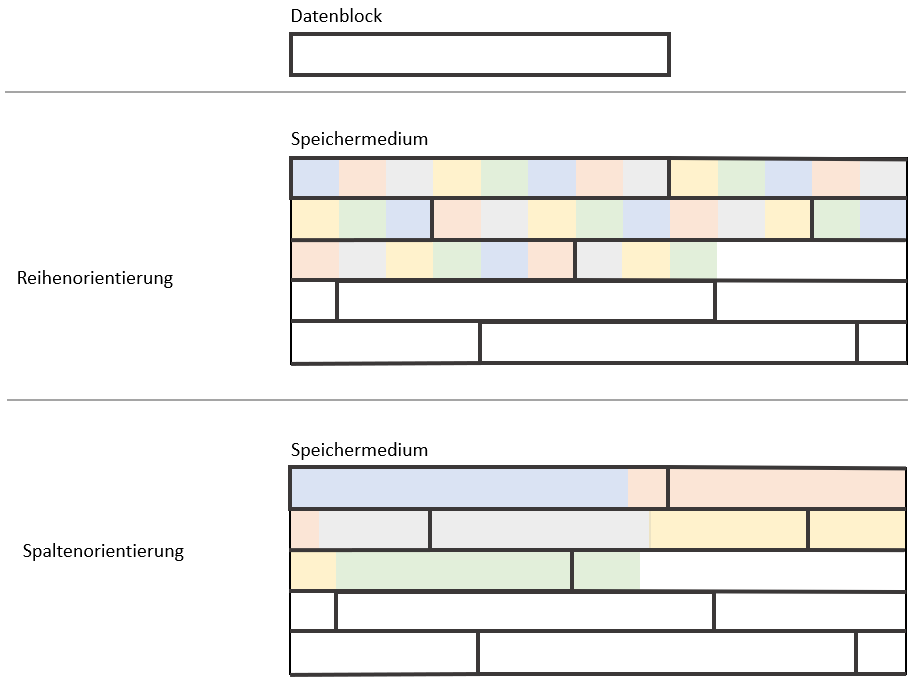
Nehmen wir nun eine nicht-analytische Datenbankoperation an: „Ändere den Nachnamen der Person, die Benjamin Abel heißt und 1987 in Köln, Deutschland, geboren ist, auf ‚Meyer‘.“ Um diese Transaktion zu bearbeiten, müssen alle Einträge der ersten Reihe gelesen werden. Sehen wir uns nun an, wo die entsprechenden Daten auf unserer schematischen Darstellung liegen würden.
Wir sehen, dass unser System in diesem Fall in einer reihenorientierten Datenbank einen einzigen Speicherblock lesen müsste, um die gesamten Daten der ersten Reihe bereit zu haben. In der spaltenorientierten Datenbank hingegen sind die Daten verteilt. Es müssen vier Datenblöcke gelesen werden und die Reihe aus diesen „rekonstruiert“ werden. Daher sprechen wir hier vom Reconstruction Overhead.
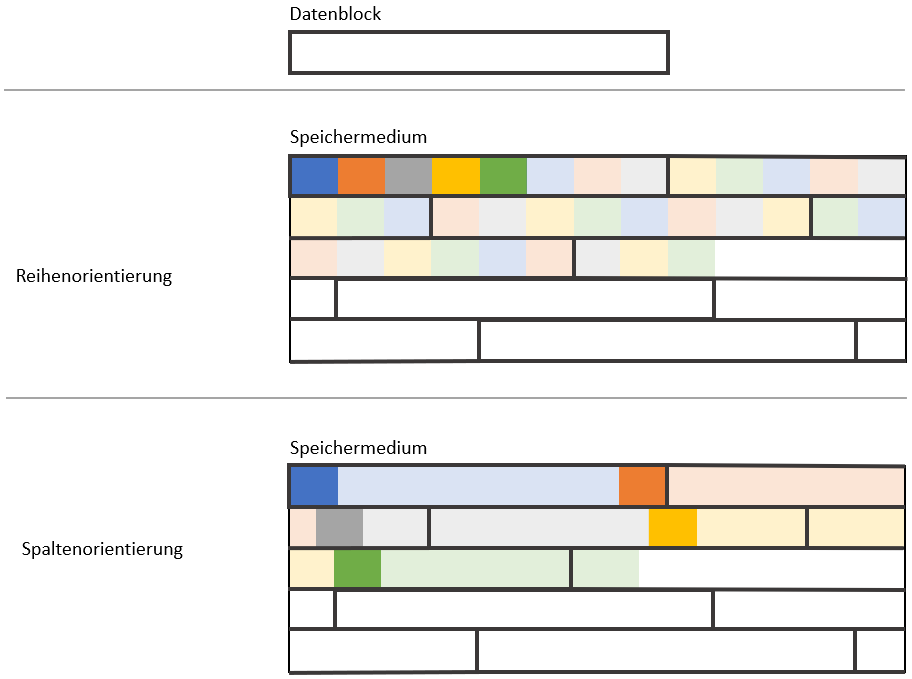
Im Fall von analytischen Anfragen haben wir das umgekehrte Problem. Angenommen, wir wollen das durchschnittliche Geburtsjahr aller Personen berechnen, stellt sich die Datenverteilung wie folgt dar.
In unserem schematischen Beispiel muss die reihenorientierte Datenbank fünf, die spaltenorientierte Datenbank nur zwei Blöcke lesen.
Der Delta Store – Das Beste aus zwei Welten
Die Hauptdatenbank der HANA DB ist spaltenorientiert. Kombiniert damit, dass alle Daten im Arbeitsspeicher liegen, lässt ihre Performance analytische Anfragen auf aktuellen, operationalen Daten zu. Um aber gute Leistung auch für transaktionale Operationen zu ermöglichen, verfügt die HANA DB über den Delta Store. Hierbei handelt es sich um eine kleinere, reihenorientierte Datenbank, die alle transaktionalen Operationen speichert und von Zeit zu Zeit mit der Hauptdatenbank synchronisiert. Durch diese Technik können mit der HANA DB bedeutende Leistungssteigerungen für alle Anfragen erreicht werden.

Auf das „Wie“ kommt es an
Die HANA DB eröffnet neue Möglichkeiten und ist herkömmlichen Datenbanken in vielerlei Hinsicht überlegen. Diese zu nutzen und ihr volles Potential zu entfalten, erfordert das richtige Knowhow. Haben Sie Fragen oder konkrete Wünsche? Gerne helfen wir Ihnen weiter, mit der HANA DB neue Wege zu gehen. Kontaktieren Sie uns einfach!



