





Der Code Pushdown – Neue Spielregeln der ABAP Programmierung auf HANA

Der Code Pushdown ist ein neues Paradigma von SAP für die ABAP Programmierung auf HANA. Doch was bedeutet das eigentlich?

Die wesentliche Innovation der HANA Datenbank besteht aus der In-Memory Technologie, also der Haltung aller Daten im Hauptspeicher, und einer starken Kopplung zwischen Rechnerarchitektur und Software, die sich in einer starken Parallelisierung durch Hierarchien und speziellen Prozessorbefehlen äußert. Dies hatten wir in Einblick in die SAP HANA Datenbank diskutiert. Welche Konsequenzen ergeben sich für die ABAP on HANA Entwicklung?
Bevor wir die Thematik näher beleuchten, lassen Sie uns zunächst kurz betrachten, wo wir uns befinden:
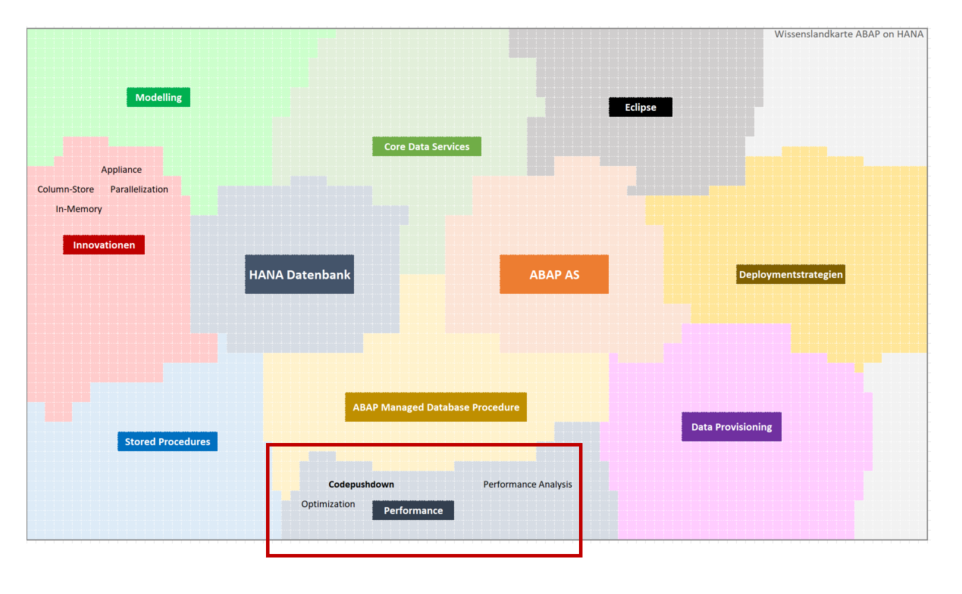
Die Verschiebung des Engpasses
Die Prinzipien der Kommunikation mit der Datenbank aus ABAP heraus, sahen bisher wie folgt aus:
- Suche effektiv nach den Daten die du benötigst
- Übertrage nicht mehr Daten, als erforderlich
- Entlaste den Datenbankserver
Zwar ist dies auch unter HANA gegeben, doch hat sich die Gewichtung dieser Regeln verschoben. Bildlich gesprochen, durchläuft der Informationsstrom bei der Verarbeitung Medien unterschiedlicher Kohäsion. Bei der Übertragung zwischen Applikationsservern und Datenbank, werden die Daten im Prinzip über ein Netzwerk übertragen, was um Größenordnungen langsamer läuft, als die serverinterne Übertragung zwischen Arbeitsspeicher und Cachehierarchie. Werden auf mechanische Bauteile, wie Festplatten, zugegriffen, fällt der Unterschied noch extremer aus.
War früher der letzte Punkt der wesentliche Engpass, verschiebt sich dieser nun durch die Datenhaltung im Hauptspeicher auf das Netzwerk. Demnach kann das Übertragungsvolumen von Datenbank zum Applikationsserver als eine wichtige Performancekennzahl typischer ABAP on HANA Anwendungen betrachtet werden.
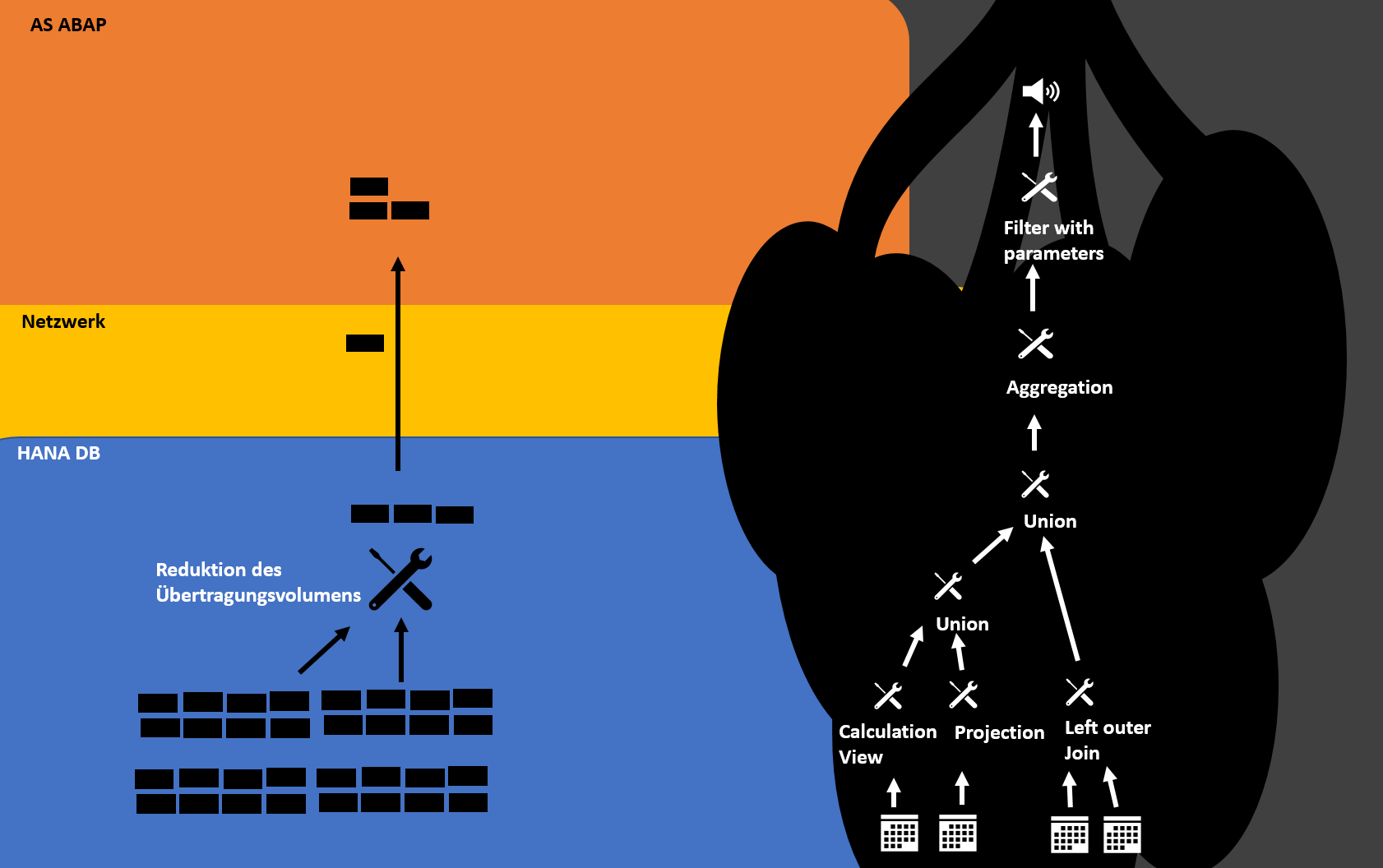
Der Codepushdown als Antwort auf neue Möglichkeiten
Diese Situation unter HANA ergibt nun neues Potential für die Beschleunigung Ihrer Anwendungen.
Das neue Paradigma heißt nun Codepushdown: statt der Datenbank mitzuteilen, welche Daten wir für die Verarbeitung benötigen – Data-to-Code – teilen wir dieser mit, wie diese Daten zu verarbeiten sind – Code-to-Data. Anstatt das Rohmaterial umständlich anzuliefern und dann zu verfeinern, lassen wir es bereits an Ort und Stelle (im Datenbankmanagementsystem), in einem dafür spezialisierten Umfeld, in ein gewünschtes End- oder Zwischenprodukt verarbeiten. Damit senken sich in der Regel die Transportkosten. Dies verschiebt natürlich eine Teillast auf den Datenbankserver. Dafür ist HANA spezialisiert und verträgt nicht nur eine solche Belastung, sondern kann diese in der Regel um ein vielfaches schneller umsetzen.
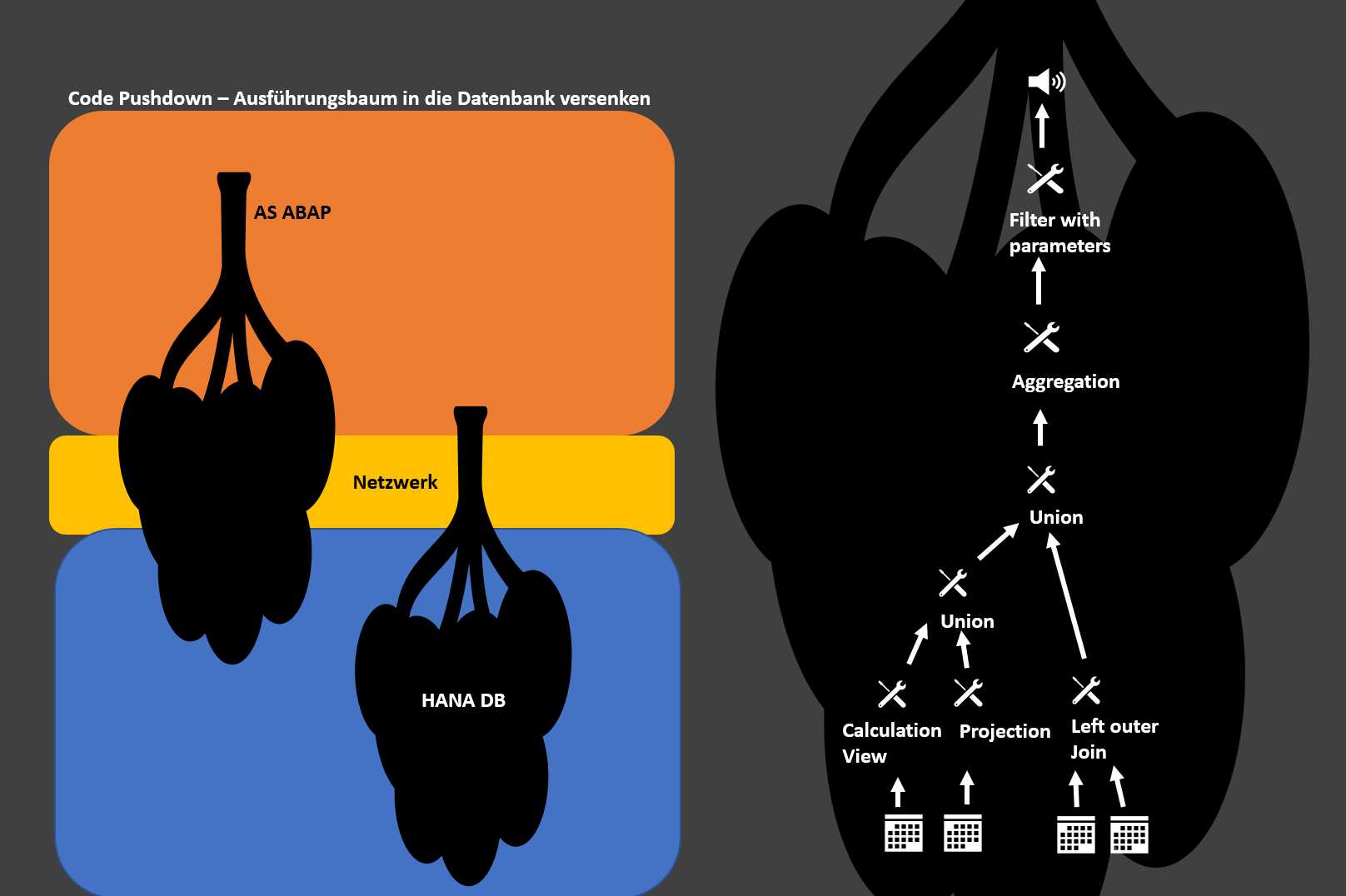
Von der Black zur Whitebox – das Innenleben beleuchten
Zur Umsetzung des Codepushdowns in ABAP, nähert sich SAP seit Netweaver 7.4 SP05 dem SQL92 Standard an. Dies geschieht durch erweiterte Ausdrucksmöglichkeiten von Views und den Zugriff auf modularisierten Datenbankcode. Die Modularisierung erfolgt in Form von sogennanten Stored Procedures, geschrieben in SQLScipt, einer dem SQL Standard um imperative Sprachelemente erweiterten Sprache. In gewisser Weise können sowohl komplexere „Gestalten“ aus der Datenbank projiziert, als auch direkt umfangreicher Datenbankcode aus ABAP verarbeitet werden, der nur noch das Resultat aus der Datenbank zurück liefert.
Der Zugriff aus ABAP erfolgt durch Proxys der Views oder Stored Procedures, also ABAP Stellvertreter dieser HANA seitigen Objekte. Oder durch die Definition von Objekten der ABAP Core Data Services (ABAP CDS) oder des klassenbasierten Frameworks der ABAP Managed Database Procedures (AMDPs).
Der Ansatz über Proxys oder CDS bzw. AMDPs führt zu Bottom-Up oder Top-Down-Ansätzen. Auf diese Ansätze werden wir zu einem späteren Zeitpunkt noch stoßen.

Ausblick – Engpässe finden und auflösen
Nach einem HANA Code Readiness Check und einer erfolgreichen Migration auf HANA, liegt der nächste wichtige Schritt in der Optimierung Ihrer Anwendungen.
Hierzu bietet SAP leistungsstarke Tools, der statischen und dynamischen Performanceanalyse an, die bei der Datensammlung, Interpretation und Engpasslokalisation, sogar unter Produktivbedingungen, unterstützen.
Wie geht’s weiter?
In den nächsten Beiträgen beleuchten wird den CDS und die AMDPs genauer, als die leistungsstarken Instrumentarien des Codepushdowns. Ferner werden wir uns die Funktionsweise der verschiedenen Tools zur Performanceoptimierung näher ansehen.



