


HANA und HANA Datenbank
Wer SAP HANA (High Performance Analytic Appliance) googled kommt mit einer ganzen Reihe von Begriffen in Berührung.
Da ist zum einen die Rede von der SAP HANA Entwicklungsplattform, ausgestattet mit der In-Memory Technologie, am Hasso-Plattner-Institut zusammen mit der Standford-University entwickelt, um den Anforderungen der Business Intelligence und Business Analytics gerecht zu werden.

Ferner clustern sich andere Begriffe rund um das Thema SAP HANA Business Suite 4 SAP HANA, kurz SAP S/4HANA. Andere Begriffe wiederum formieren sich rund um das Thema HANA Cloud Platform (SAP Cloud Platform seit dem 27. Februar 2017).
Suchen wir nach Gemeinsamkeiten, so stellen wir fest, dass alle oben genannten Technologien, als zugrunde liegendes Datenbank-Management-System (DBMS) die SAP HANA Datenbank verwenden.
Um HANA im Kern besser zu verstehen, werde ich mich hier auf die Perspektive eines Anwendungsentwicklers aus der klassischen SAP Umgebung fokussieren, der nun erstmalig Anforderungen in einer SAP HANA Umgebung umsetzt. Ebenfalls passend wäre die Sicht als IT-Verantwortlicher, der nun vor der Herausforderung steht, sein Team auf die Zukunft mit HANA vorzubereiten.
Leitfragen zur HANA Datenbank
Lassen Sie uns in dieser kleinen Serie von Beiträgen tiefer in das System HANA DB eintauchen und ein Stück weit klären, welchen neuen Herausforderungen wir uns stellen werden, und welche Fähigkeiten und neuen Denkweisen wir hierbei erlernen müssen.
Nun haben wir die HANA DB bereits als System bezeichnet. Erlauben Sie mir im Sinne dieser Denkweise konsequent fortzufahren.
Hierdurch ergeben sich einige Leitfragen, die wir im Laufe der Serie näher im Detail beleuchten wollen:
- Was ist neu in der “HANA-Welt”? Wie verläuft die Kommunikation über die Grenzen hinweg?
- Welchen Zweck erfüllt die HANA DB?
- Durch welche Faktoren wird die Entwicklung der Technologie getrieben?
- Wie unterscheidet sich die HANA DB von den ursprünglichen relationalen Datenbanken?
- Aus welchen Komponenten besteht die HANA DB und wie interagieren diese?
- Welche datenbankspezifischen Objekte gibt es?
- Welche Prozesse laufen in und über die HANA DB?
- Was sind Perspektiven und welche sind für Entwickler auf der HANA DB wesentlich?

HANA im Kraftfeld zwischen Innovation und gestiegenen Anforderungen
Ein wesentliche Treiber der Entwicklung ist die Analyse großer Datenmengen. War zuvor eine strikte Trennung von transaktionaler und analytischer Funktionalität erforderlich, wird diese Lücke nun ein Stück weit wieder geschlossen. Während sich transaktionale Berechnungen durch das Lesen, Verändern und Schreiben einzelner weniger Datensätze auszeichnen, greifen analytische Prozesse großräumig auf Daten von weniger Attributen zu, um sie für ein anschließendes Berichtswesen in konsolidierter Form aufzubereiten.

Tabellen müssen im Speicher linearisiert werden.
Hier spricht man von einem transponierten Zugriff auf Datenbanktabellen. Während der transaktionale Zugriff horizontal geschieht, wird bei analytischem Zugriff vertikal auf die Daten der Tabelle zugegriffen. Nicht zuletzt die Berücksichtigung dieser geänderten Zugriffsart zeichnet HANA für analytische Szenarien aus.
Abgrenzung HANA DB und Any-DB – In-Memory
Was zeichnet die HANA DB von einer bis hierin üblichen relationalen Datenbank, einer Any-DB, aus? Durch kostengünstigere Hauptspeicher, die immer mehr Kapazität tragen, liegt die Idee nahe, immer mehr Daten im Hauptspeicher für einen schnelleren Zugriff zu puffern. Gehen wir nun soweit, dass im Wesentlichen alle Daten so abgelegt werden, erhalten wir einen wesentlichen Aspekt der In-Memory Technologie. Hieraus ergeben sich einige Konsequenzen und Probleme.
Die Größe aller Geschäftsdaten einer Applikation kann im mehrstelligen Terabyte Bereich liegen. Es werden dadurch geeignete Komprimierungsverfahren benötigt. Für einen schnellen Zugriff über eine Anwendung, sollten die hierfür benötigten Informationen nahe im Speicher beieinander liegen, um die Zahl der Seitenfehler im Cache zu reduzieren.
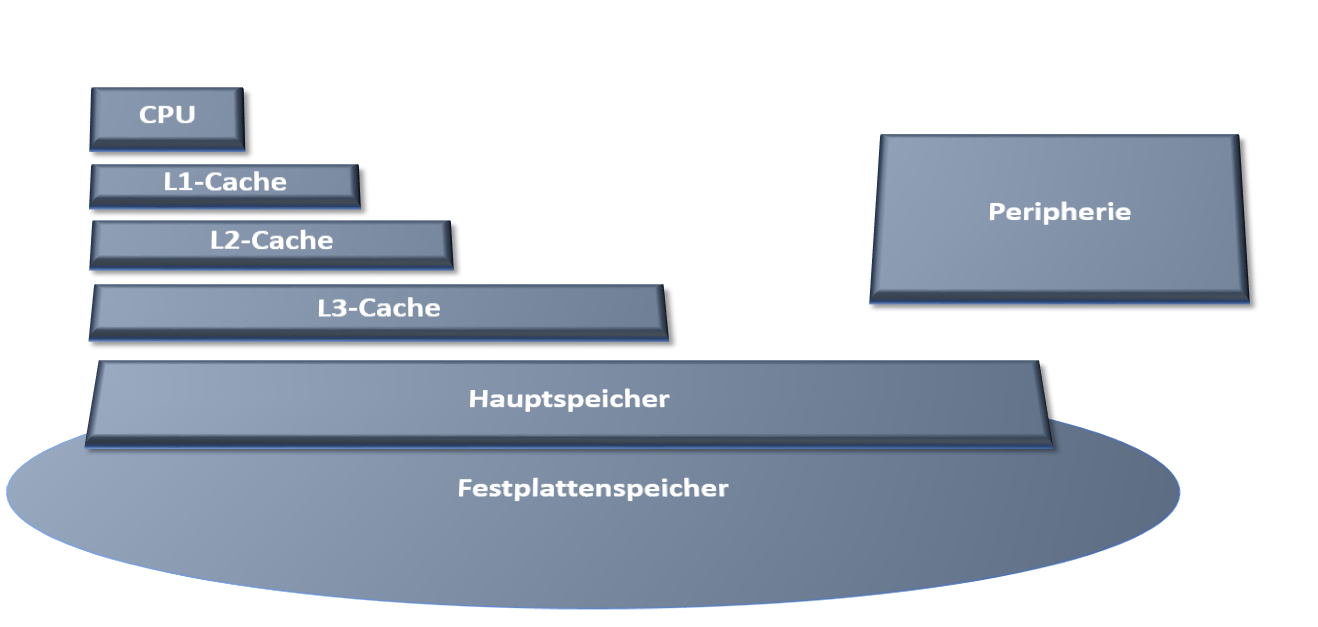
Moderne Speicherhierachien
Wir sprechen in diesem Zusammenhang auch von Datenlokalität. Aus zuvor genannten Gründen der geänderten Zugriffsweise durch analytische Prozesse, liegt nun die Überlegung nahe, dass Seitenlayout von Datenbanktabellen in HANA zu transponieren. Anstatt, wie im zeilenbasiertem Layout, einzelne Zeilen der Tabelle sukzessiv hintereinander zu schreiben, und damit die Spalten der Tabelle zu zerschneiden, bleiben im spaltenbasierten Layout die einzelnen Spalten zusammen und werden hintereinander weggeschrieben. Hiermit erhält man wiederum neue Angriffspunkte für die dringend benötigte Komprimierung.
Spaltendekomposition
Jede Spalte wird nun durch einen Attribut- und Dictionary-Vektor in der Datenbank repräsentiert. Das Dictionary umfasst in sortierter Weise die verschiedenen Werte der Spalte. Im Attributvektor werden nun die Positionen der Werte im Dictionary-Vektor weggeschrieben.
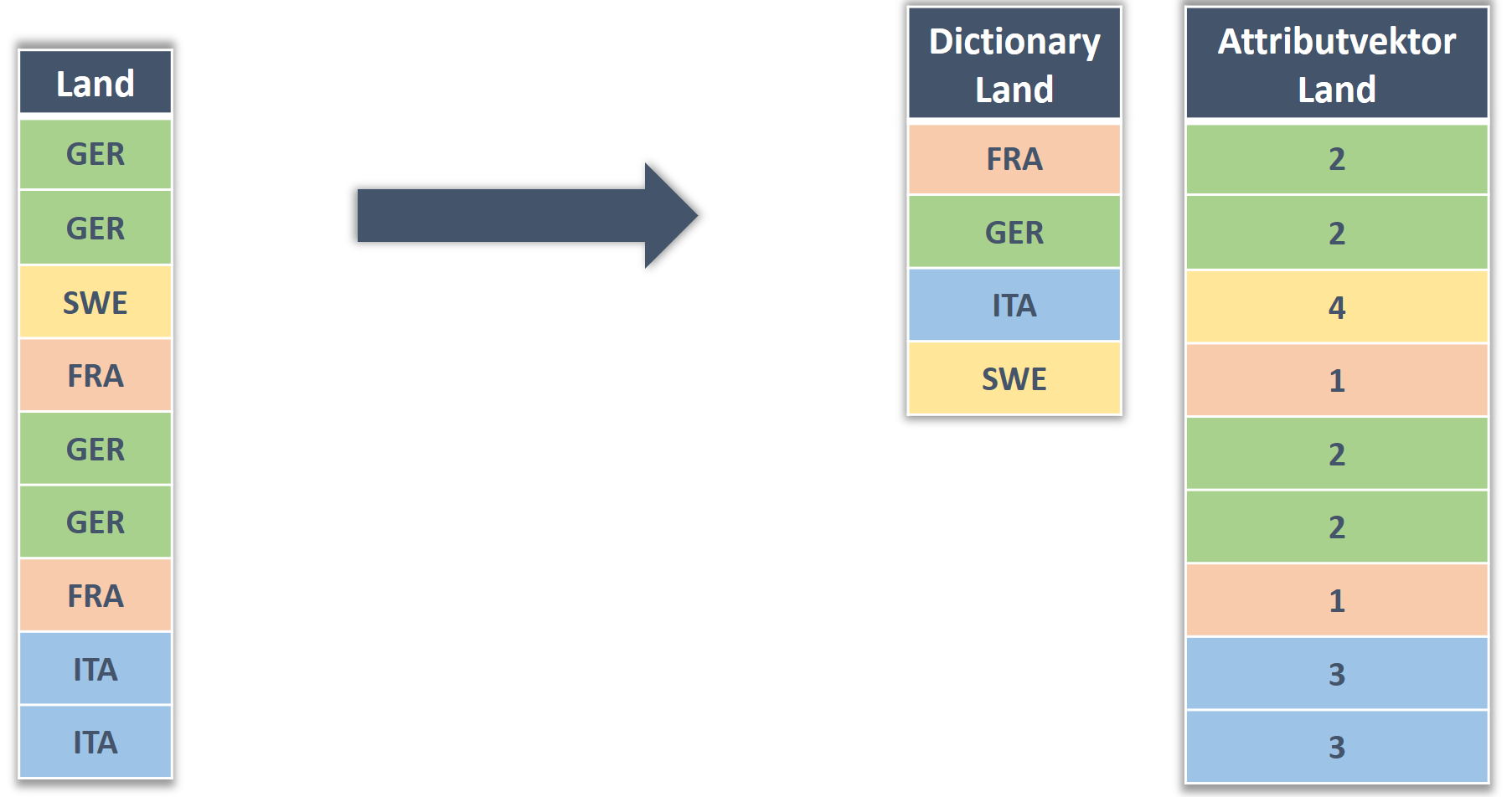
Dekomposition in Dictionary und Attributvektor
Sowohl auf das Dictionary, als auch auf den Attributvektor können nun geeignete Komprimierungen durchgeführt werden. So lässt sich schnell vorstellen, dass in typischen Geschäftstabellen, viele Spalten nur wenig verschiedene Werte besitzen. Ein gutes Beispiel dafür sind Währungseinheiten.
Aufeinanderfolgende Werte im Attributvektor können somit durch den Wert und die Anzahl codiert werden. Der erzielte Komprimierungsfaktor, i.e. das Verhältnis aus komprimierter und unkomprimierter Speichergröße, schwankt in typischen Anwendungen je nach Spalte zwischen 20% und 140%, wobei das Gesamtergebnis üblicherweise deutlich vorteilhafter ist.
Weitere wesentliche Vorteile eines spaltenbasierten Layouts für analytische Berechnungen, liegen in einer deutlich verbesserten Möglichkeit der Parallelisierung. Zum Beispiel, dass mehrere Spalten unabhängig voneinander aggregiert werden können.
Appliance
Diese Möglichkeiten nutzt HANA durch eine Appliance, also einer starken Kopplung zwischen Hard- und Software. Auf Ebene der Prozessorkerne einer HANA kompatiblen Maschine, finden wir eine SMID-Architektur, deren Operationen auf die speziellen Bedürfnisse analytischer Geschäftsprozesse hin optimiert sind. Weiter finden sich eine hierarchische Anordnung mit Kernen, Prozessoren, Blades und Racks.
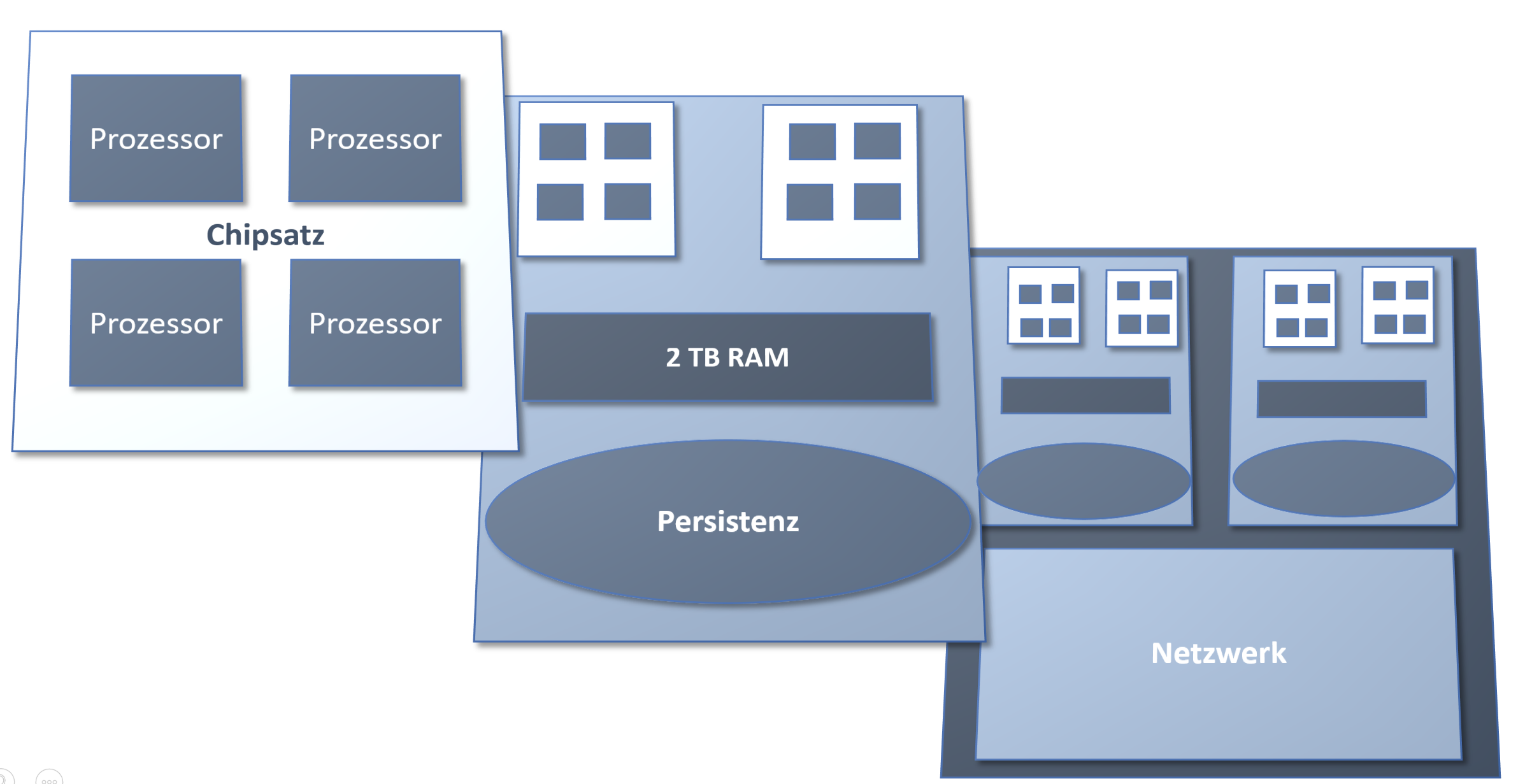
Mehrkernhierarchien
Zusammenfassung
Zusammengefasst können wir nun folgendes festhalten:
- HANA verwendet eine relationale Datenbank mit der In-Memory Technologie.
- Hierbei werden die Geschäftsdaten üblicherweise spaltenbasiert im Hauptspeicher gehalten.
- Das spaltenbasierte Layout begünstigt zum einen durch geeignete Datenlokalität die Berechnung durch analytische Prozesse.
- Andererseits wird auch die Parallelisierung begünstigt.
- HANA optimiert diese Prozesse durch eine geeigneten SMID-Prozessorarchitektur und eine auf Parallelisierung ausgerichtete Hierarchie von berechnenden Einheiten und Speicher.
Wie geht es weiter?
In der nächsten Folge klären wir das fundamentale Prinzip des Code-to-Data Prinzips. Wir erläutern, wie dieses Prinzip einen neuen Engpass in der Datenverarbeitung zu beantworten versucht. Wir zeigen, wieso Core Data Services (CDS) und in SQLScript geschriebene ABAP Managed Database Procedures, sogenannte AMDPs, bald zu einen Muss im Werkzeugkasten eines jeden ABAP Softwareentwicklers werden.
Wie bereiten Sie sich und Ihre Mannschaft auf die Zukunft vor?
FAQ
Was ist SAP HANA?
SAP HANA ist die neue Datenbanktechnologie von SAP und bietet gerade für die Anwendung mit BIG DATA große Vorteile. Die Datenbanktechnologie ist ein Grundpfeiler der neuesten SAP Erp Version SAP S/4HANA.
Für was steht Hana?
HANA steht in Zusammenhang mit SAP für: High Performance Analytic Appliance.
Wer kann mir beim Thema SAP HANA Datenbank – ein Einblick helfen?
Wenn Sie Unterstützung zum Thema SAP HANA Datenbank – ein Einblick benötigen, stehen Ihnen die Experten von Erlebe Software, dem auf dieses Thema spezialisierten Team der mindsquare AG, zur Verfügung. Unsere Berater helfen Ihnen, Ihre Fragen zu beantworten, das passende Tool für Ihr Unternehmen zu finden und es optimal einzusetzen. Vereinbaren Sie gern ein unverbindliches Beratungsgespräch, um Ihre spezifischen Anforderungen zu besprechen.
