





S/4HANA Cloud als “Intelligent ERP” – Was ist Machine Learning?

Machine Learning (ML) ist in aller Munde und hat sich besonders in den letzten Jahren als Begriff im Alltag etabliert. So nennt auch die SAP Machine Learning als wesentlichen Bestandteil der Idee des "intelligenten ERP" S/4HANA Cloud. Doch was ist eigentlich Machine Learning und wann kann Machine Learning eingesetzt werden?
Um diese Fragen zu beantworten, mache ich Sie zunächst mit grundlegenden Begriffen der ML-Welt vertraut und gebe Ihnen dann ein erstes Modell zur Entscheidungshilfe zur Hand, wann Machine Learning eingesetzt werden kann.

Was ist Machine Learning?
Der Begriff Machine Learning ist an den Begriff des Lernens angelehnt, wie wir es aus dem Alltag kennen. Wenn Menschen lernen, nehmen sie Informationen auf, machen Erfahrungen und nutzen diese für zukünftige Situationen.
Analog geht es bei Machine Learning darum, dass Computer aus vorhandenen Daten Erkenntnisse ziehen und diese nutzen, um mit neuen, unbekannten Daten umzugehen. Das heißt, Computer können über ML-Algorithmen Daten analysieren und von sich aus Entwicklungen vorhersagen, neue Daten kategorisieren, Handlungsvorschläge geben und vieles mehr. Doch bevor wir uns mit den verschiedenen Arten des Machine Learnings beschäftigen, machen wir einen kurzen Ausflug in die ML-Terminologie.
Machine Learning Terminologie
Ein fertiges ML-System, das Ergebnisse liefert, wird Modell genannt. Ein Modell bekommt Eingabedaten (Input) und generiert aus diesen eine Ausgabe (Output). Damit dieses Modell auch die richtigen Ergebnisse liefert, wird es trainiert. Das bedeutet, es bekommt als Input Trainingsdaten, und wird dem gewünschten Output entsprechend angepasst.

Kategorisierung von Machine Learning
Grundsätzlich lässt sich Machine Learning aus zwei Blickwinkeln betrachten: einerseits wird unterschieden, nach welcher Methode ein Modell trainiert wird, andererseits danach, welche Funktion das Modell nach dem Training hat. Das illustriert die folgende Abbildung. Die englischen Begriffe wurden dabei beibehalten, da diese meist auch in der Praxis verwendet werden.
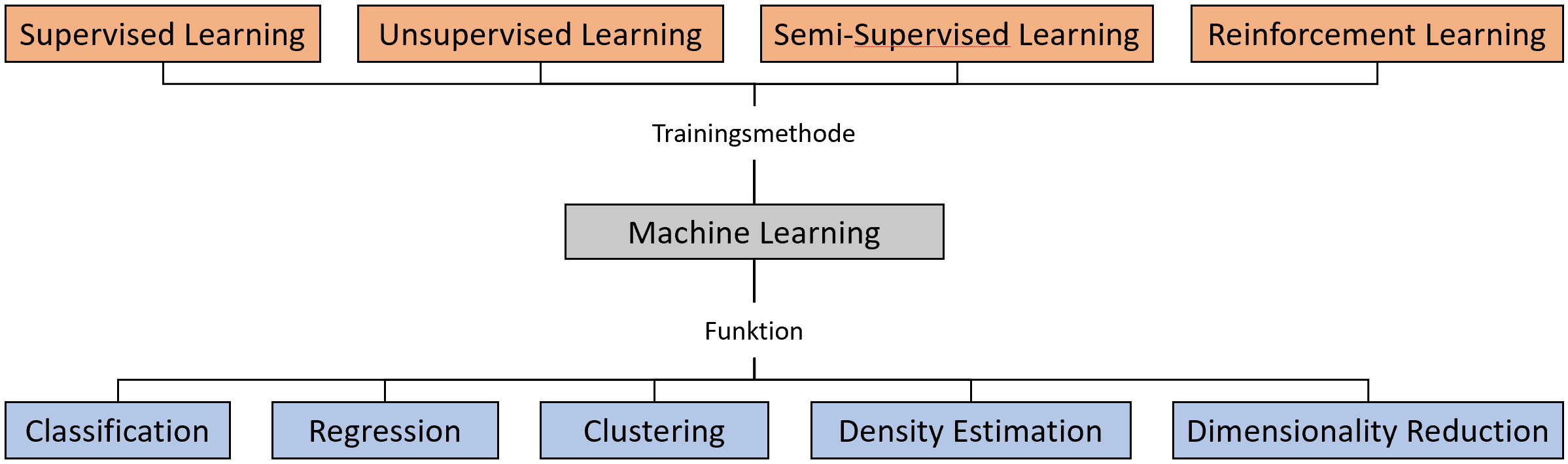
Unterscheidung nach Trainingsmethode
Die Trainingsmethoden lassen sich in erster Linie dadurch unterscheiden, wie das Ziel definiert ist, nach dem ein Algorithmus das Modell generiert. Im Supervised Learning (dt. überwachtes Lernen) ist genau vorgegeben, welcher Output aus einem bestimmten Input generiert werden soll und dahingehend „überwacht“. Input-Daten sind jeweils mit einem „Label“ (= gewünschter Output) versehen.
Das Modell wird während des Trainings anhand der Diskrepanz zwischen erwünschtem Output und tatsächlichem Output angepasst. Diese Methode eignet sich beispielsweise für die Kategorisierung von Bildern. Im Unsupervised Learning hingegen wird das Modell ohne festgelegtes Ziel generiert, der Algorithmus nutzt ungelabelte Daten und findet das Ergebnis von sich aus. Entsprechend wird im Semi-Supervised Learning eine Mischung aus gelabelten und ungelabelten Daten genutzt.
Im Reinforcement Learning wird ein zu erreichendes Gesamtziel vorgegeben (z.B. „erreiche eine möglichst hohe Punktzahl im Spiel Tetris“), in dem ein Modell in seinen zielführenden Handlungen „bestärkt“ wird.
Unterscheidung nach Funktion
Eine weitere Möglichkeit, Machine-Learning- Algorithmen einzuteilen, ist die Unterscheidung nach der Funktionalität des gewonnenen Modells.
In einer Classification (Klassifikation) wird jeder Input einer bestimmten Kategorie zugeordnet. Mit dieser Technik können beispielsweise Objekte auf Bildern erkannt oder Texte nach Thema sortiert werden. Regression wird genutzt, um Werte zu erzeugen, die nicht bekannt sind. Ein Beispiel ist hier die Vorhersage des Preisverlaufs eines Produkts (Output) auf Grundlage der Preise des letzten Monats (Input).
Clustering wird genutzt, um Daten zu gruppieren. Density Estimation (Kerndichteschätzung) kann verwendet werden, um die Wahrscheinlichkeit einer Zufallsvariable zu schätzen. Im Zuge einer Dimensionality Reduction (Dimensionenreduktion) können Daten auf ihre wesentlichen, wichtigen Attribute reduziert werden. Beispielsweise könnte ein Ziel sein, anhand von Daten männliche und weibliche Löwen zu unterscheiden. Ein ML-Modell könnte feststellen, dass das Gewicht eines Löwen für die Unterscheidung hilfreicher ist als die Farbe des Fells, und diese ignoriert werden kann.
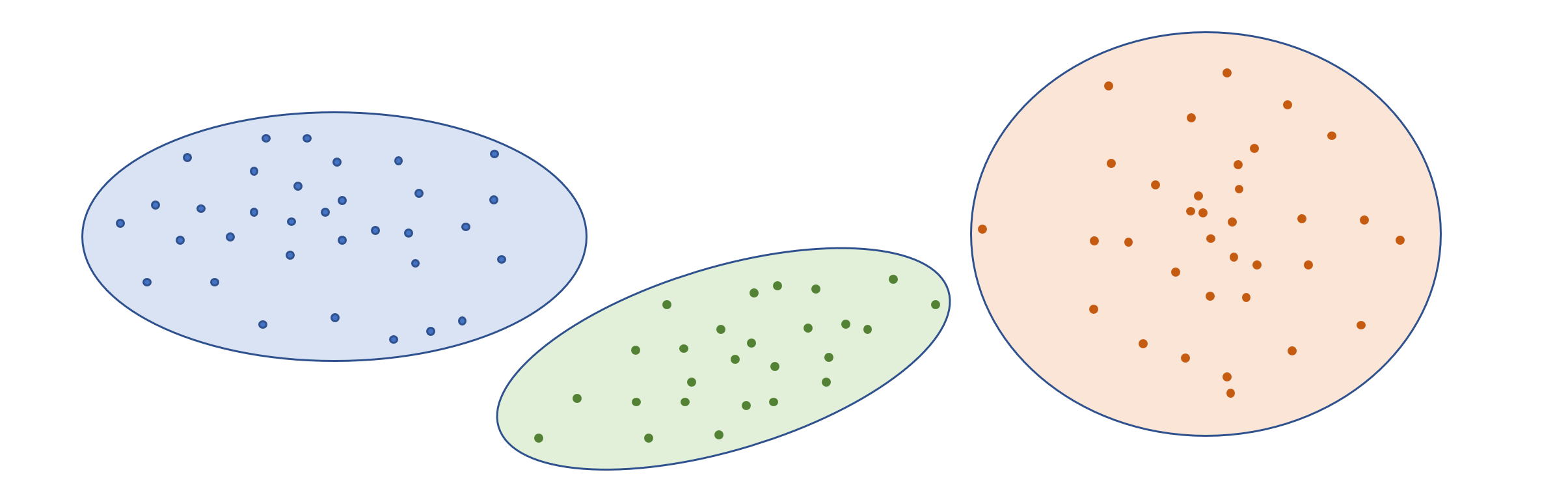
Illustration Clustering: Datenpunkte, die zusammengefasst werden können, werden demselben Cluster zugeordnet.
Wann kann Machine Learning eingesetzt werden?
Nicht jedes Problem kann mit Machine Learning sinnvoll gelöst werden. So können manchmal regelbasierte KI-Programme zielführender sein (Beispiel: „Wenn ein Auftrag mit Priorität ‚hoch‘ angelegt wird, sende eine Benachrichtigung an Bearbeiter XY“). Können wir also eine Problemlösung durch feste Regeln definieren, ist eine regelbasierte KI die bessere Lösung als eine ML-Lösung. Um aber eine erste Intuition dafür zu bekommen, wann eine Machine-Learning-Lösung infrage kommt, können wir uns am folgenden Diagramm orientieren.
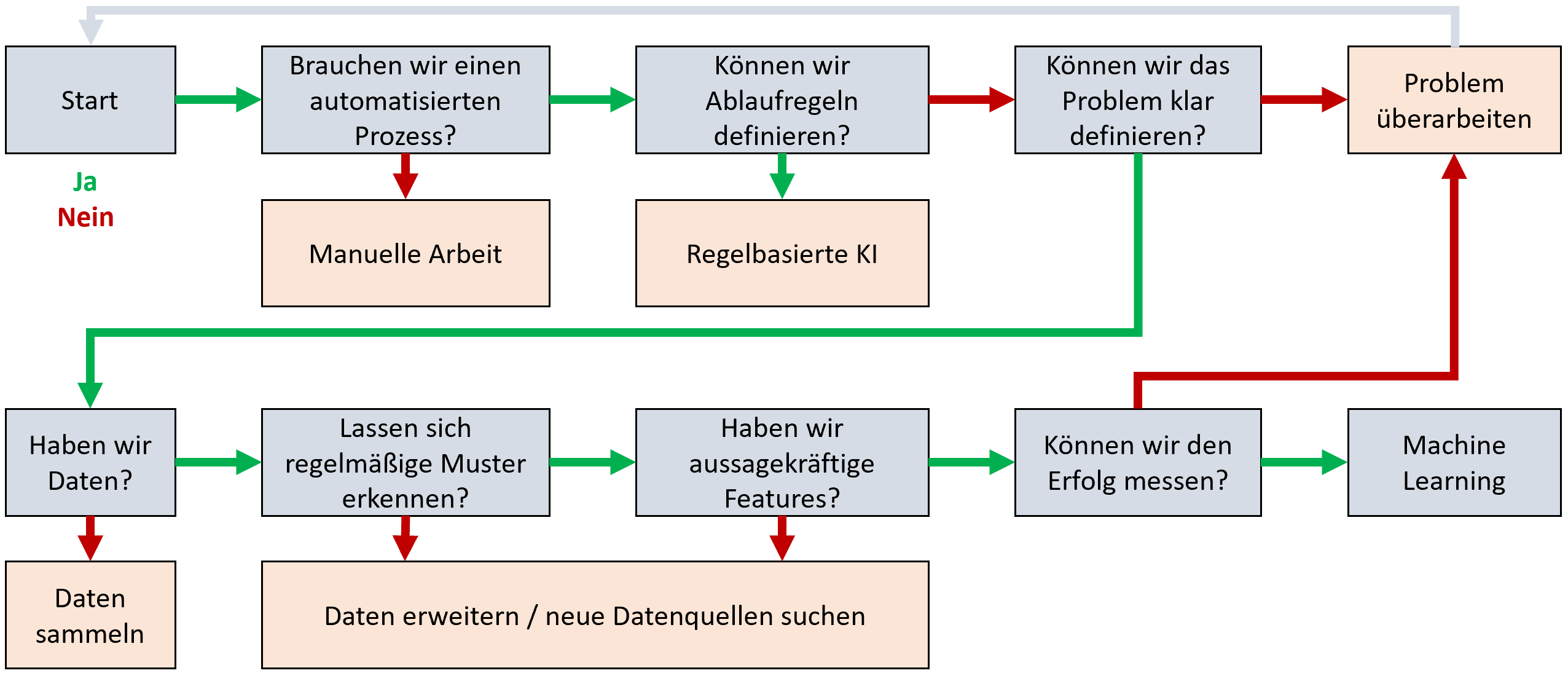
Machine Learning – Zwischen Theorie und Nutzen
Ich hoffe, es ist mir gelungen, Ihnen mit diesem Blogeintrag den Einstieg in das Thema Machine Learning zu erleichtern. Einige der Punkte waren zugegebenermaßen sehr theoretisch. Da stellt sich die Frage, wie diese Konzepte in der Praxis sinnvoll eingesetzt werden können. Die SAP aktiv daran, Machine Learning in S/4HANA Cloud unkompliziert zugänglich zu machen, um Prozesse zu automatisieren, zu vereinfachen und zu verschnellern.

Aber welche ML-Funktionalitäten bietet S/4HANA Cloud eigentlich? Wie können konkrete Use-Cases aussehen? Um diese Fragen geht es im nächsten Beitrag zu S/4HANA Cloud Intelligent ERP. Haben Sie Fragen zu Machine Learning? Kommentieren Sie oder schreiben Sie uns, wir helfen gerne weiter.
Weitere Quellen: openSAP



