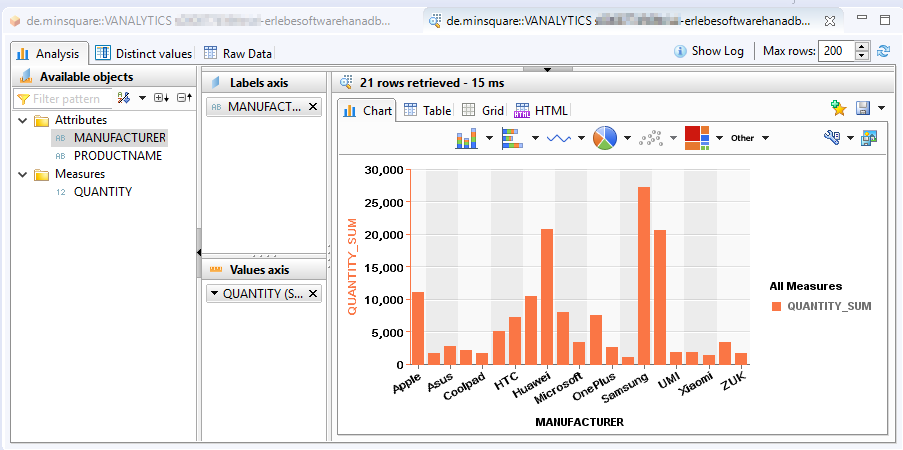
Für alle, die einmal einen Blick auf die SAP HANA Plattform und insbesondere auf die HANA Datenbank mit ihren speziellen Funktionen werfen wollen, gibt es eine einfache Möglichkeit: Die SAP Cloud Platform bietet in der Trial Edition bereits die Möglichkeit, eine HANA DB testweise in Betrieb zu nehmen. Das ist genau die richtige Option, um ein wenig mit der neuen Technologie zu experimentieren.
Die wichtigsten Schritte für ein erstes Hands-on-SAP-HANA-DB
- Trail Account anlegen
- Datenbank und Schema anlegen
- Eclipse einrichten
- Eclipse mit der cloud verbinden
- Einen Benutzer anlegen
- Beispieldaten importieren
- Analytic View erstellen
1. Trail Account anlegen
Über https://cloudplatform.sap.com/try.html kann jeder einen Developer Account einrichten.
2. Datenbank und Schema anlegen
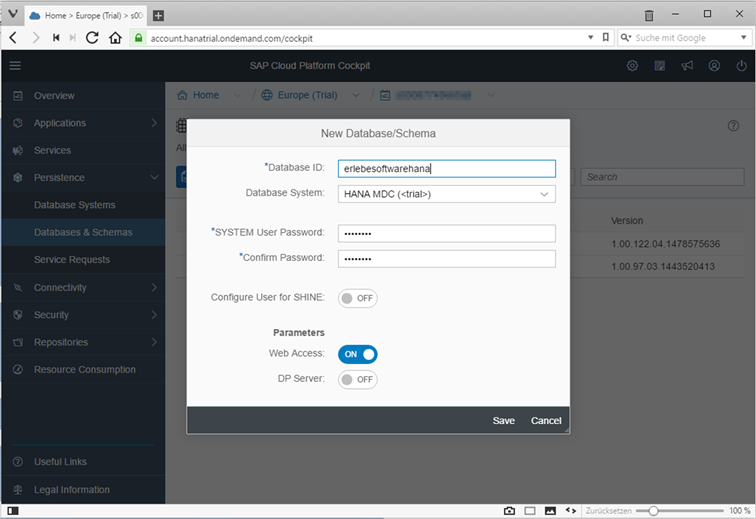
Im Bereich Persistence im Cloud Platform Cockpit wird eine Datenbank und ein Schema angelegt.

Die Datenbank braucht eine ID und für den Start ein Passwort für den SYSTEM User.
Es dauert ein paar Minuten, bis die Datenbank angelegt und gestartet ist.
Danach ist die HANA Instanz verfügbar und kann über verschiedene Webtools administriert werden.Achtung: Weil es sich um eine Trial Instanz handelt, wir diese automatisch nach einigen Stunden heruntergefahren.
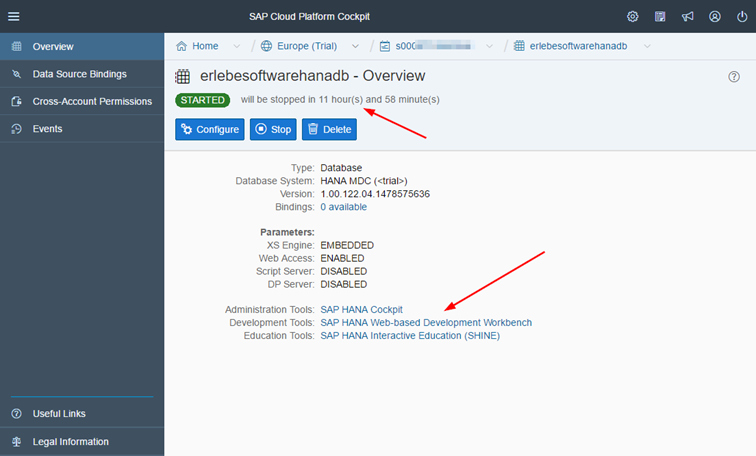
So sieht zum Beispiel die Adminoberfläche im Fiori-Style aus.
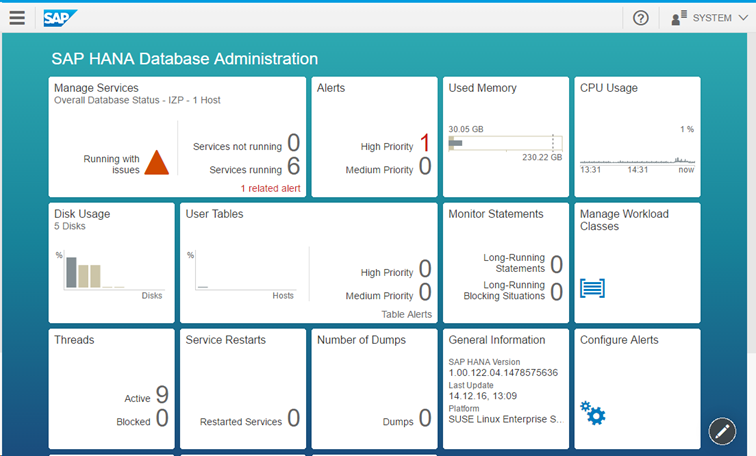
3. Eclipse einrichten
Als Entwicklungsumgebung kommt bei uns jetzt eclipse NEON zum Einsatz.Der Download erfolgt direkt hier:http://www.eclipse.org/neon/

In eclipse dann den Bereich für die Plug In Installation öffnen.
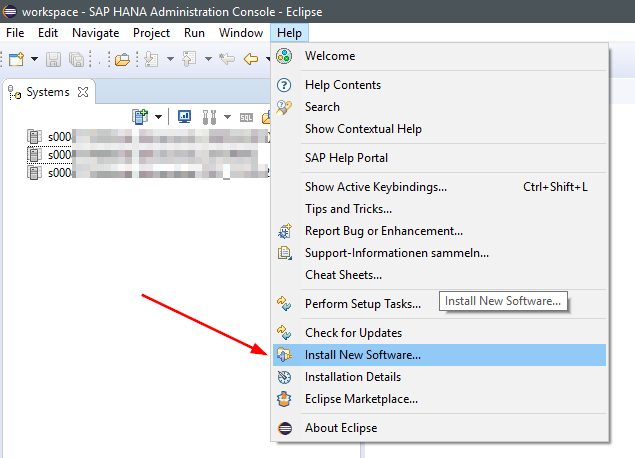
Unter der Update Site https://tools.hana.ondemand.com/neon/sind die hier gezeigten Plug Ins verfügbar.Wir brauchen die SAP HANA Tools.

4. Eclipse mit der cloud verbinden
Dazu zuerst die Perspektive SAP HANA Development öffnen.
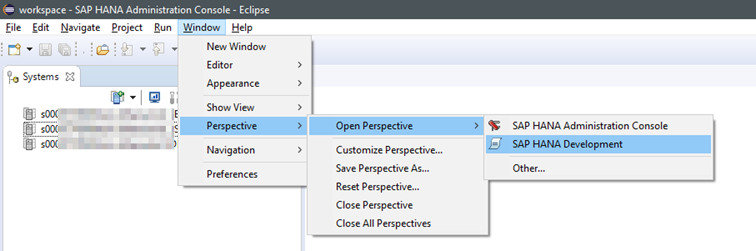
Ein neues Cloud System hinzufügen
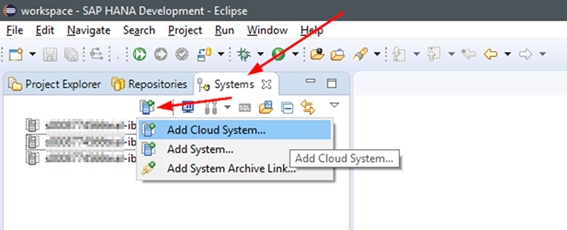
Die Verbindungdaten umfassen wie immer auf der Cloud Platform erstens den Account, zweitens den User drittens das Passwort.
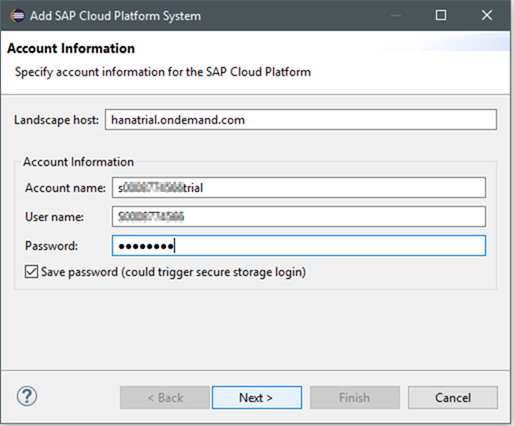
Jetzt erst kommt die eben gestartete Datenbank und der SYSTEM User zum Einsatz.
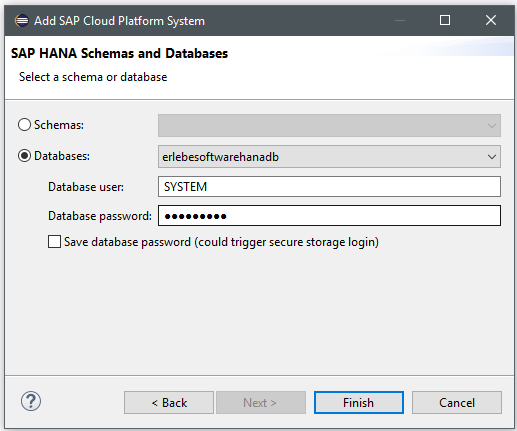
So ist dann die Datenbank eingebunden und zeigt einiges an System-Objekten.
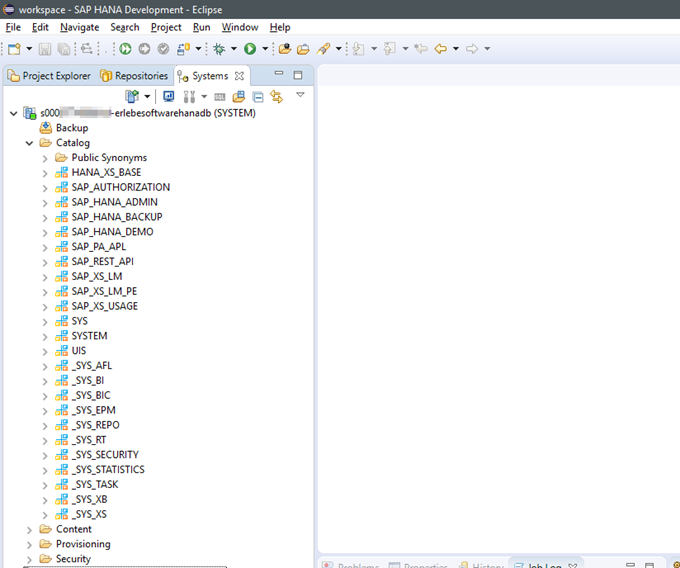
5. Einen Benutzer anlegen
Theoretisch könnte man min dem SYSTEM User weiterarbeiten. Aber wir erstellen einen eigenen Benutzer für die spätere Arbeit.
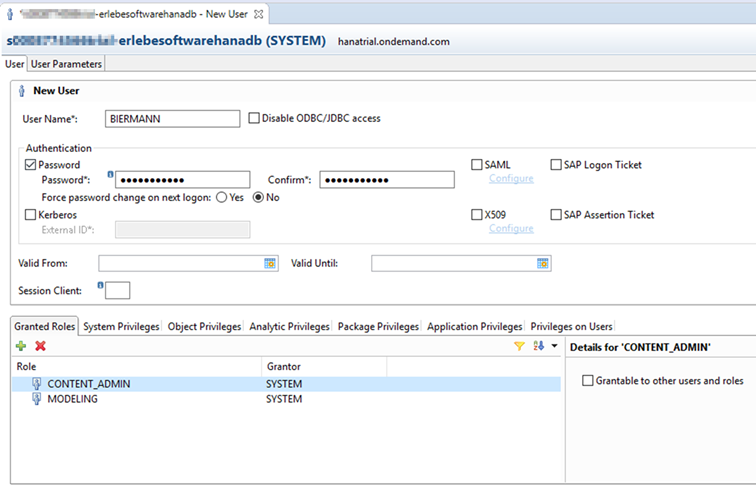
Zwei Rollen sind vorerst erforderlich: CONTENT_ADMIN und MODELING (hier Speichern nicht vergessen).
Wenn man jetzt das gleiche System nochmal wie oben beschrieben anbindet, kann der neue User genutzt werden.Es sind also zwei Verbindungen aktiv.

6. Beispieldaten importieren
Wir haben hier drei Beispieldateien bereitgestellt, die als Testdaten herhalten. Den nützlichen Wizard startet man zum Beispiel über das globale Menü: File > Import > SAP HANA Content > Data from File
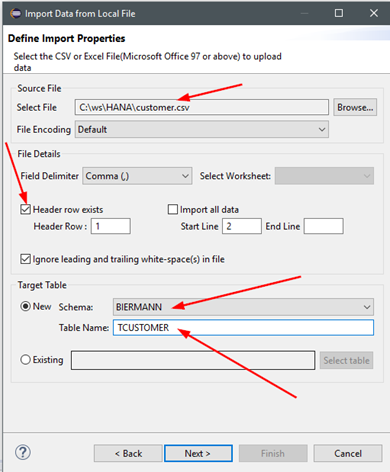
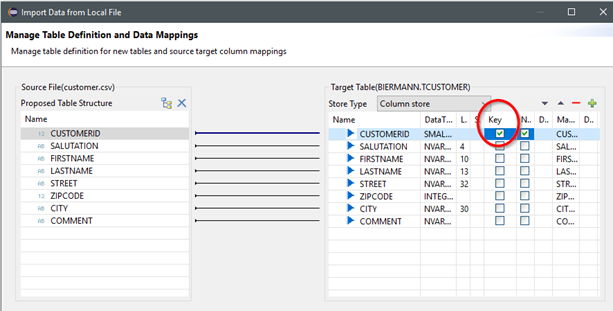
Geben Sie nacheinander die drei Testdaten-Files an, zusammen mit diesen Optionen:Header Row exists (es werden Spaltennamen abgeleitet)Schema: Hier zum Start mal das Home-Schema des eigenen Benutzers wählen.Table Name: Einen schönen Tabellennamen ausdenken.
Der Importassistent schlägt Einiges sinnvoll vor. Ergänzen sollte man jeweils das Key-Flag für die Spalten CUSTOMERID und PRODUCTID in den drei vorgeschlagenen Tabellen.
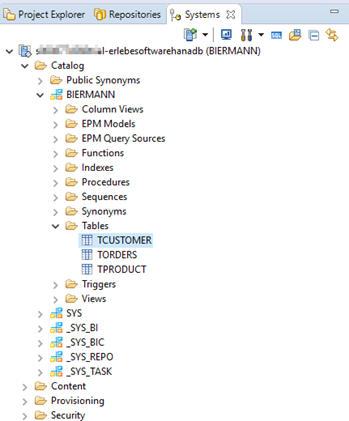
So sehen die drei Tabellen dann im Schema aus
Über das Kontextmenü lässt sich auch der Inhalt einfach anzeigen.

7. Analytic View erstellen
Im Prinzip ist jetzt schon alles möglich, was die HANA DB an einfachen und erweiterten Datenbankfunktionen bietet.Wir erstellen beispielhaft einen sogenannten Analytic View, der als Basis für Echtzeitdatenanalyse dienen kann.Dazu benötigen wir zuerst im Bereich Content ein beliebiges Package und dort dann ein entsprechendes Objekt.

In den Bereich Data Foundation des Analytic Views werden dann die drei erstellten Tabellen gezogen.
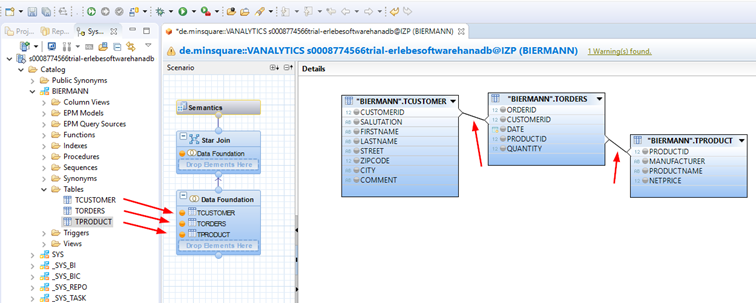
Außerdem erstellt man per Maus Relationen zwischen den Schlüsselfeldern und wählt die Felder, die im Output zu sehen sein sollen (diese werden dann Orange dargestellt).

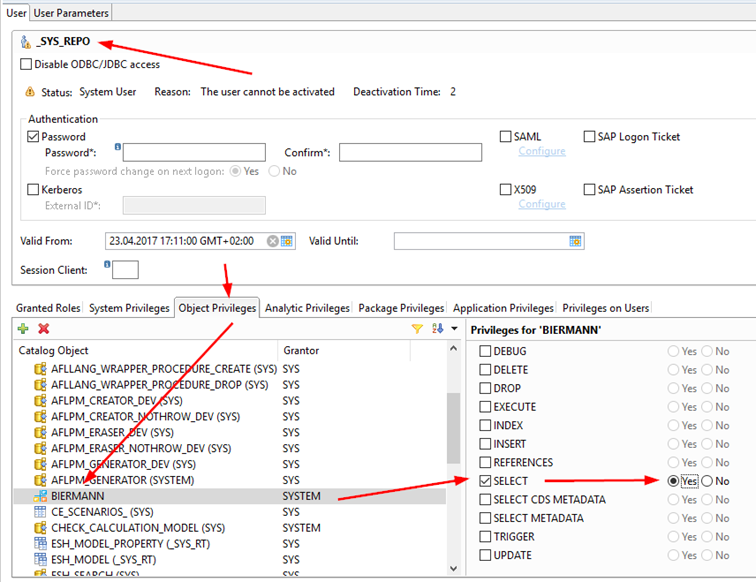
Einen Trick benötigt es noch:Der User _SYS_REPO benötigt auf dem neu erstellten Schema bestimmte Berechtigungen, wie hier zu sehen.Damit kann dann später der Analytic View aus der Design-Time in die richtigen Runtime Objekte umgesetzt werden.
Im Bereich Semantics wird jetzt definiert, welches der Felder als Attribut und welches als Kennzahl behandelt werden soll.
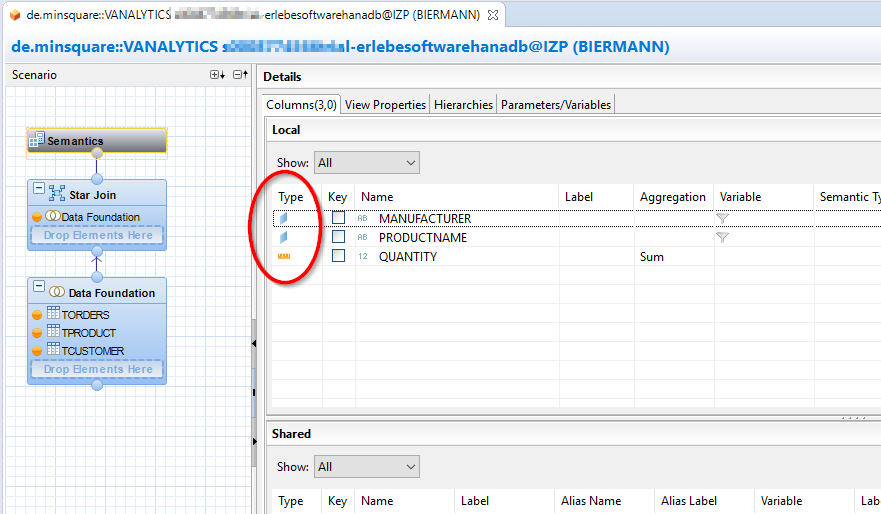
Wenn der Analytic View fertig ist kann er in bekannter SAP Weise zunächst validiert werden und dann im System aktiviert werden.Über Data Preview ist dann eine Inplace Vorschau innerhalb von eclipse möglich.
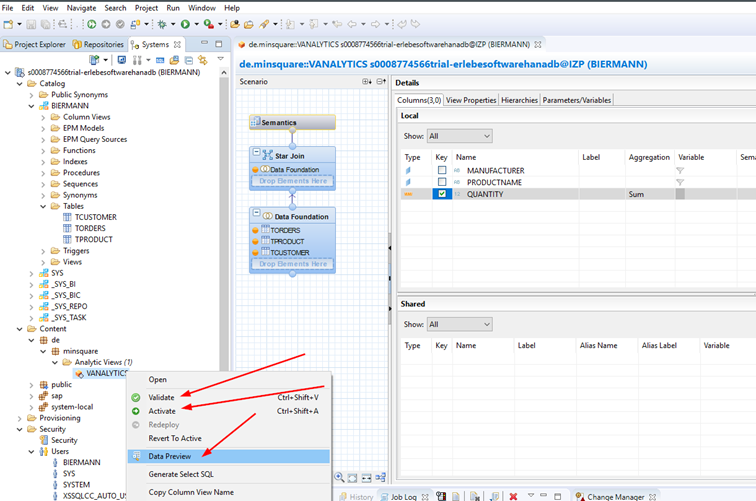
Die Möglichkeiten sind vielfältig – viel Spaß beim Testen mit der SAP HANA DB.